- Cloud Database Insider
- Posts
- Drone Strikes Hit AWS Data Centers in UAE & Bahrain⚠️|Amazon OpenSearch enables zero ETL🚀|Microsoft Fabric unifies data teams🤖
Drone Strikes Hit AWS Data Centers in UAE & Bahrain⚠️|Amazon OpenSearch enables zero ETL🚀|Microsoft Fabric unifies data teams🤖
Deep Dive: A Look Into Microsoft Fabric, Part 3: MS Fabric Medallion Architecture
Gladstone Benjamin
March 09, 2026
In partnership with
What’s in today’s newsletter:
Drone Strikes Hit AWS Data Centers in UAE & Bahrain⚠️
Amazon OpenSearch enables zero ETL🚀
Microsoft Fabric unifies data teams with AI-driven analytics 🤖
SQL Server vs Oracle: Which DB Fits You?⚔️
Also, check out the weekly Deep Dive - MS Fabric Medallion Architecture
🤝 Sponsor Cloud Database Insider
Reach 3,400+ senior data architects, engineers, and platform leaders working with Snowflake, Databricks, PostgreSQL, and modern AI data stacks.
How can AI power your income?

Ready to transform artificial intelligence from a buzzword into your personal revenue generator
HubSpot’s groundbreaking guide "200+ AI-Powered Income Ideas" is your gateway to financial innovation in the digital age.
Inside you'll discover:
A curated collection of 200+ profitable opportunities spanning content creation, e-commerce, gaming, and emerging digital markets—each vetted for real-world potential
Step-by-step implementation guides designed for beginners, making AI accessible regardless of your technical background
Cutting-edge strategies aligned with current market trends, ensuring your ventures stay ahead of the curve
Download your guide today and unlock a future where artificial intelligence powers your success. Your next income stream is waiting.
AWS

TL;DR: Drone strikes on AWS data centres in the Gulf caused outages, exposing security gaps in protecting cloud infrastructure from hybrid warfare and prompting a need for stronger physical and cyber defenses.
Drone strikes targeted AWS data centres in the Gulf, causing outages and service disruptions.
These attacks highlight the rise of drone technology in hybrid warfare against digital infrastructure.
The incident reveals security gaps in protecting cloud infrastructure from physical and cyber threats.
It may prompt cloud providers to enhance physical security and influence international digital protection norms.
Why this matters: The Gulf drone strikes reveal critical vulnerabilities in cloud infrastructure, threatening global businesses reliant on AWS. This hybrid warfare escalation forces cloud providers to bolster physical protections, signaling a pivotal shift in security strategies and international policy around safeguarding digital assets in conflict zones.

TL;DR: Amazon OpenSearch Service now offers zero ETL integrations with native connectors, enabling direct data streaming that reduces complexity, costs, and delays while boosting real-time analytics and decision-making.
Amazon OpenSearch Service introduces zero ETL integrations to enable direct, automated data streaming from sources.
Native connectors for Amazon Kinesis Data Firehose and AWS IoT SiteWise simplify real-time data ingestion.
The new feature reduces operational complexity and costs while accelerating time-to-insight for businesses.
This advancement strengthens OpenSearch as a scalable, user-friendly solution for diverse analytics and monitoring needs.
Why this matters: Zero ETL integrations with Amazon OpenSearch Service remove data pipeline complexities, reducing costs and delays. This enables faster, real-time insights critical for industries like security and IoT, boosting operational agility and reinforcing OpenSearch’s role as a scalable, efficient platform for modern analytics demands.
DATA PLATFORMS

TL;DR: Microsoft Fabric unifies data workflows with OneLake, AI, and low-code tools, enabling collaboration, secure governance, and democratized analytics to accelerate data-driven decisions and foster innovation enterprise-wide.
Microsoft Fabric unifies data engineering, science, and business intelligence into one integrated analytics platform.
OneLake provides a single data source, enabling collaboration and eliminating organizational data silos.
Built-in AI, compliance controls, and low-code tools enhance real-time analytics, security, and user accessibility.
The platform accelerates data-driven decisions, democratizes analytics, and fosters innovation across all skill levels.
Why this matters: Microsoft Fabric streamlines complex data tasks into one platform, breaking down silos and accelerating insights. Its AI and low-code tools empower teams of all skill levels, enhancing security and collaboration. This enables faster, data-driven innovation and decision-making, crucial for maintaining competitiveness in today’s data-centric market.
RELATIONAL DATABASES
TL;DR: Oracle excels in advanced features and complex workloads but is costlier, while SQL Server offers affordability and Microsoft integration; the best choice depends on business needs, scalability, cost, and IT strategy alignment.
Oracle Database excels in advanced features, security, multi-platform support, and high-performance complex workloads.
SQL Server offers competitive pricing, user-friendly interface, and strong integration within Microsoft product ecosystems.
Choosing between these databases affects scalability, analytics capabilities, budgeting, staffing, and operational efficiency.
Licensing, vendor support, and alignment with IT strategy are critical factors influencing total cost and reliability.
Why this matters: Choosing between Oracle and SQL Server shapes an organization's data management, costs, and operational efficiency. Oracle suits complex, multi-platform needs with higher costs, while SQL Server appeals for ease, Microsoft integration, and affordability. Aligning choice with strategy ensures better scalability, analytics, and long-term support.

EVERYTHING ELSE IN CLOUD DATABASES
Palantir’s AI OS aims for $150+ billion growth
Redis vs Postgres: Best State for Long Agents
Snowflake swaps Debezium for OpenFlow ease
Databricks unveils ZeroBus Ingest for speedy streaming
Druva Leverages Graphs to Boost Metadata Mining
Yggdrasil's Data Journey: BigQuery to AWS Lakehouse
MinIO Boosts On-Prem AI Data Access for Databricks
ParadeDB boosts PostgreSQL query performance
Simplify data workflows with Snowflake OpenFlow
Replit Launches Enterprise Data App with Databricks
Graph DBs power AI, fight fraud & track data lineage
PlanetScale launches MCP server for database scaling
Data Management Trends Shaping 2026
Spark SQL powers fast, flexible big data queries.
Data Governance: Crucial in GenAI Era
Databricks Adds Nasdaq Data Via Delta Sharing
Databases Cut Costs, Boost Innovation Fast
Amplitude Boosts Analytics with NLP & OpenSearch Vector DB
DEEP DIVE
A detailed look into Microsoft Fabric, Part Three, Medallion Architecture
Part One of the Deep Dive
I am indeed a sucker for hosted events by vendors. I attended another hands on training from Databricks last week. I had to overcome my aversion to the TTC to get there. I even got somewhat lost and had to circle back from Museum station (the one with the cool columns) to Queens Park station. Good thing I left early that morning.
That whole preamble about my questionable navigation skills is to say that the Databricks folks as well as the other hosts, Compass, mentioned the idea of the Platinum layer in the Medallion Architecture.
I thought to myself “this lines up with the Deep Dive for the upcoming newsletter”. But then I thought that from my cursory glances at Microsoft Fabric, they only espouse 3 layers in some cases. Well, this is not about the ambitious Databricks, but the Medallion Architecture in Microsoft Fabric.
Let’s talk about it.
1. Architectural Philosophy: The Fabric-Native Medallion Framework
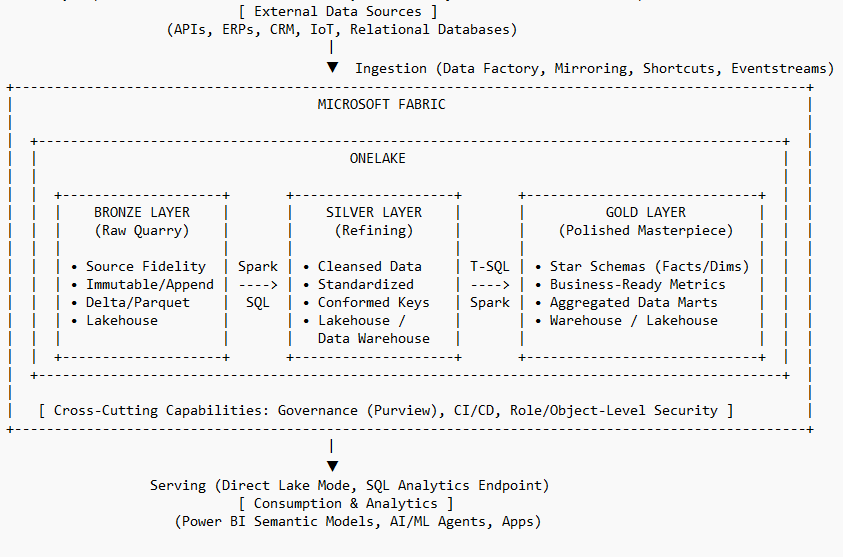
The enterprise data landscape has shifted from fragmented, proprietary silos to the unified, Software-as-a-Service (SaaS) lakehouse model. Microsoft Fabric operationalizes this shift through OneLake—a singular, logical data lake for the entire organization—and the "OneCopy" principle. This architecture eliminates the need for data duplication across services by utilizing the open Delta Lake format. By leveraging Delta Parquet as the universal storage standard, multiple compute engines (Spark, T-SQL, and Power BI) operate on the same physical data, ensuring ACID compliance while providing the transactional reliability of a traditional warehouse at data lake scale.
The Medallion framework is a multi-hop design pattern that progressively improves data quality and structure. It is an architectural mandate that ensures data maturity is explicit and governed.
Feature | Traditional Data Warehouse | Microsoft Fabric Lakehouse |
Storage Model | Proprietary, Structured Only | Unified OneLake (Delta Parquet) |
Data Format | Relational / Closed | Open (Delta Lake, Parquet, JSON, CSV) |
Compute Flexibility | T-SQL Only (Coupled) | Decoupled (Spark, T-SQL, KQL, Power BI) |
Data Movement | Complex ETL/Data Movement | OneCopy / Virtualized Shortcuts |
Governance | Localized to Database | Centralized (Microsoft Purview / OneLake) |
Architects must utilize OneLake Shortcuts to virtualize data from external cloud storage (ADLS Gen2, S3, GCS) or other Fabric workspaces. This strategy is essential to reduce egress costs and eliminate versioning issues, allowing downstream layers to reference upstream data without physical duplication.
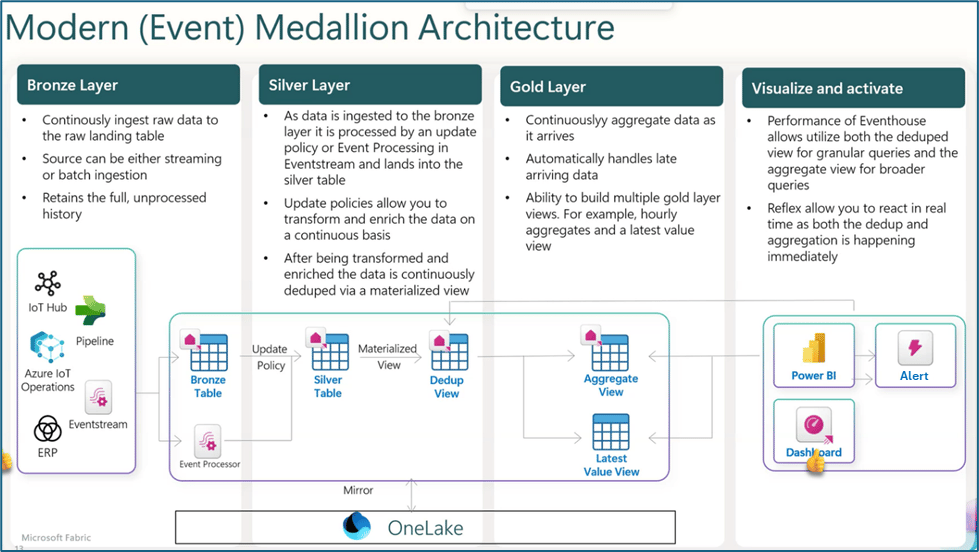
2. The Bronze Layer: Engineering Raw Fidelity and Ingestion
The Bronze layer serves as the Raw Landing Zone, functioning as the immutable entry point for all data entering the Fabric ecosystem. Its primary objective is the preservation of source fidelity. Architects must enforce an append-only approach to maintain a complete historical archive, ensuring that data can be reprocessed if business requirements or downstream logic evolve.
Ingestion Mechanisms and Strategic Choice
Data in Bronze remains in its original format to provide a technical audit trail. For relational sources, architects should prefer Delta tables in the Bronze "Tables" section to support efficient Change Data Capture (CDC) and transactional guarantees. Unstructured or native files should reside in the "Files" section.
Data Factory Pipelines: The standard for batch-oriented data movement from on-premises or cloud-based APIs and storage.
Fabric Mirroring: A zero-ETL capability for continuous, real-time replication of databases (e.g., Azure SQL, Snowflake) directly into OneLake.
Eventstreams: Required for high-velocity telemetry (IoT, logs), capturing real-time events for landing into a Lakehouse or KQL database.
OneLake Shortcuts: Used to "virtualize" external data in place, minimizing ingestion latency and storage overhead.
Mandatory Technical Metadata
Every Bronze asset must be augmented with the following technical columns to ensure auditability and lineage:
Metadata Column | Description |
IngestionTimestamp | UTC date and time when the record was loaded into the Bronze layer. |
SourceFileName | The name of the original file (required for file-based ingestion). |
SourceSystemID | A unique identifier for the originating source system. |
PipelineRunID | The unique ID of the pipeline or notebook that executed the load. |
3. The Silver Layer: Architecting the "Trusted" Enterprise View
The Silver layer acts as the Data Quality Gate, where data is matched, merged, and conformed into a standardized "Enterprise view." This layer provides domain-neutral business entities (e.g., Master Customer, Order History) that serve as the single source of truth for cross-departmental analysis.
Standard Operating Procedure for Silver Transformations
Transformations must focus on harmonizing disparate sources into a canonical schema via:
Type Casting: Enforcing consistent types (e.g., ISO 8601 date formats) and casting numeric strings to decimals.
Null Handling: Applying business rules to manage missing data via default values or filtering.
Standardization: Normalizing units of measure, currency (e.g., conversion to USD), and address formats.
Anonymization: Mandatory PII masking or removal to comply with GDPR/privacy regulations.
Technical Implementation: Spark vs. Materialized Lake Views
For complex, large-scale wrangling, Spark Notebooks are the preferred tool, utilizing the Delta MERGE operation for incremental updates and deduplication. Alternatively, Materialized Lake Views (MLVs) provide a SQL-native, declarative method. MLVs are recommended for SQL-centric teams as they handle automatic dependency management and optimal refresh logic that Spark notebooks require manual orchestration to achieve.
Advanced Data Integrity and SCD Type 2
Architects must leverage Deletion Vectors to ensure deleted data is excluded from queries without immediate, expensive file rewriting. For auditing and historical tracking, the following 4-step Slowly Changing Dimension (SCD Type 2) logic must be implemented in Spark:
Identify Unchanged Data: Match incoming Bronze records against active Silver records.
Process New/Updated Records: Assign StartDate, set EndDate to NULL, and mark as 'Active'.
Deactivate Obsolete Records: Close out modified source records by setting EndDate to current UTC and status to 'Inactive'.
Manage Surrogate Keys: Generate unique surrogate keys to maintain dimensional model integrity.
4. The Gold Layer: Curation for High-Performance Consumption
The Gold layer shifts focus from domain-neutral reliability to project-specific curation. Data must be modeled into Kimball-style Star Schemas (Fact and Dimension tables). This structure is a non-negotiable requirement for Power BI performance, as it enables optimal VertiPaq compression.
High-Performance Connectivity: Direct Lake Mode
Direct Lake is the transformative connectivity standard in Fabric. It allows Power BI to read Delta tables directly from OneLake with in-memory performance, bypassing the latency of DirectQuery and the duplication of Import mode.
Mode | Performance | Data Movement | Latency |
Import | High | Full Replication | Scheduled (High Latency) |
DirectQuery | Lower | None (Federated) | Near Real-Time |
Direct Lake | High | None (In-place) | Near Real-Time |
Direct Lake Optimization Best Practices
V-Order Sorting: A proprietary write-time enhancement that reorders data to align with VertiPaq compression. This is mandatory for Gold tables to accelerate read speeds.
Warming the Cache: Architects should implement a post-refresh query to preload key columns into memory, minimizing "cold start" latency for end users.
Upstream Cleansing: All calculations and data cleaning must be performed in the Gold layer tables, not within the BI semantic model.
Framing Management: The semantic model must be "framed" (synchronized) via API or pipeline immediately after the ETL completes to ensure version consistency.
5. Compute Strategy: Selecting Spark vs. T-SQL for the Medallion Pipeline
Fabric provides compute flexibility where multiple engines share OneLake storage. The T-SQL engine (Warehouse) is serverless and bin-packed, allowing it to start sessions in milliseconds, whereas the Spark engine (Lakehouse) typically incurs a ~5-second startup latency.
Category | Spark (Lakehouse) | T-SQL (Warehouse) |
Developer Profile | Data Engineers / Scientists | BI Developers / SQL Analysts |
Logic Storage | Notebooks / Spark Job Definitions | Stored Procedures / Views / Functions |
Cost Efficiency | Large-scale batch transformations | Small, frequent relational queries |
Latency | ~5-second cluster startup | Millisecond session startup |
The Hybrid Pattern Recommendation
Architects should adopt a Hybrid Pattern: Use the Spark engine for the "heavy lifting" of cleansing and merging data (Silver layer) and use the T-SQL Warehouse engine for final Gold layer modeling and serving. This leverages Spark's parallel processing for massive volumes and T-SQL's concurrency and familiarity for BI serving.
💡 Enjoy deep dives like this?
Companies building developer and data infrastructure sponsor Cloud Database Insider to reach enterprise data teams.
6. Technical Specification: Storage Optimization and Performance Tuning
The "small file problem"—where excessive metadata degrades query speed—is addressed in Fabric through two native "no-knobs" features:
Optimize Write: Performs a pre-write shuffle to create fewer, larger files.
Auto-Compaction: Automatically merges small files into larger ones after the write is committed.
Tuning Specifications by Layer
Layer | Optimization Strategy | Technical Configuration |
Bronze | Write-Optimized | Disable V-Order and Stats Collection to maximize ingestion speed. |
Silver | Balanced | Optimize for file sizes between 157MB and 500MB. |
Gold | Read-Optimized | Enable V-Order; target 1GB file sizes for maximal VertiPaq efficiency. |
Optimal File Size Targets
SQL Analytics Endpoint: ~400 MB per file for high-concurrency relational reads.
Direct Lake Mode: 400 MB to 1 GB to maximize VertiPaq row group compression.
Spark Processing: 128 MB to 1 GB to maximize vertical parallelism.
Liquid Clustering is recommended over traditional partitioning for tables under 1TB. It avoids the rigid, manual hierarchy of folders and adapts to changing query patterns without the maintenance overhead of Z-Ordering.
7. Security and Governance Guardrails: Enforcing Enterprise Standards
Fabric utilizes a multi-layered security model where governance is an integrated framework rather than an isolated restriction.
Security Implementation and Guardrails
Row-Level (RLS) & Column-Level Security (CLS): Enforced at the OneLake level, ensuring these rules are respected across Spark, SQL, and Power BI.
Workspace Role Bypass: Architects must note that users in Admin, Member, or Contributor roles typically bypass granular RLS/CLS. Access for business consumers must be managed via the Viewer role or specific Item-level permissions to ensure security logic is enforced.
Microsoft Purview Sensitivity Labels: Labels (e.g., "Highly Confidential") must be applied to assets; these labels persist through the Medallion lifecycle, ensuring data protection travels with the data.
Lifecycle Management
The data estate must be managed via Deployment Pipelines and Git Integration. This allows for the versioning of notebooks and schemas and the automated promotion of assets through Dev, Test, and Prod. Deployment rules should be used to automatically update data source connections as items move between environments.
8. Advanced Horizons: Real-Time Intelligence and the Platinum Layer
The Real-Time Medallion
In Real-Time Intelligence (RTI), data lands in Bronze KQL tables via Eventstreams. Update Policies (functioning as triggers) immediately parse and enrich data as it lands in Silver. Materialized Views in Gold provide "latest value" results for live dashboards with sub-second latency.
The Platinum Layer (AI Readiness)
The Platinum layer is a semantic extension of Gold, designed to provide the "grounding" necessary for AI and Copilots to deliver explainable, traceable insights.
Ontology (Semantic Spine): Establishes cross-domain definitions in Microsoft Purview to ensure AI understands entity relationships.
Semantic Models: Certified Power BI models with DAX context that act as the interface for AI reasoning.
Agentic Utilization: AI Agents (Copilots) interact with the Platinum layer, ensuring they reason over certified metrics rather than raw, uncontextualized data.
12-Week Implementation Playbook
Phase | Timeline | Primary Activities | Deliverables |
Foundations | Weeks 1-2 | Workspace setup; Git integration; Domain identification. | Dev Environment; Metric Catalog |
Ingestion | Weeks 3-6 | Implement CDC/Batch to Bronze; build Silver standardized areas. | Functional Bronze/Silver Layers |
Curation | Weeks 7-9 | Star Schemas in Gold; implement RLS/CLS logic. | Gold Data Marts; Power BI Reports |
Hardening | Weeks 10-12 | V-Order scheduling; Operational Monitoring; Runbooks. | Production-Ready Pipelines |
The disciplined structure of the Medallion framework in Microsoft Fabric provides the essential foundation for turning raw data ore into the polished, high-value insights required for the modern AI-driven enterprise. By organizing data into distinct stages of trust and quality, organizations effectively manage big data complexity while ensuring world-class performance and governed, explainable intelligence.
Gladstone Benjamin
🚀 Work With Cloud Database Insider
Looking to reach enterprise data engineers and architects?
Limited sponsorship slots available each month.