- Cloud Database Insider
- Posts
- AWS+Oracle join forces to boost multicloud use☁️|Databricks Hits $5.4B Revenue Run Rate🚀|TimescaleDB Outperforms MongoDB and ClickHouse🏎️
AWS+Oracle join forces to boost multicloud use☁️|Databricks Hits $5.4B Revenue Run Rate🚀|TimescaleDB Outperforms MongoDB and ClickHouse🏎️
Deep Dive: Databricks Genie Code
Gladstone Benjamin
April 20, 2026
In partnership with
What’s in today’s newsletter:
Oracle and AWS deepen multicloud collaboration for enterprises☁️
Databricks hits $5.4B, revolutionizing data intelligence🚀
TimescaleDB leads in time-series speed, scalability🏎️
Also, check out the weekly Deep Dive - Databricks Genie Code

Tech moves fast, but you're still playing catch-up?
That's exactly why 200K+ engineers working at Google, Meta, and Apple read The Code twice a week.
Here's what you get:
Curated tech news that shapes your career - Filtered from thousands of sources so you know what's coming 6 months early.
Practical resources you can use immediately - Real tutorials and tools that solve actual engineering problems.
Research papers and insights decoded - We break down complex tech so you understand what matters.
All delivered twice a week in just 2 short emails.
CLOUD COMPUTING

TL;DR: Oracle and AWS expanded their multicloud partnership to enable seamless software use across both clouds, enhancing migration, integration, and management for improved enterprise performance and cost efficiency.
Oracle and AWS have expanded their multicloud partnership to enhance customer cloud capabilities and flexibility.
The collaboration enables customers to run Oracle software on AWS infrastructure seamlessly and vice versa.
Joint efforts focus on improving migration, integration, and management across the two cloud environments.
This partnership aims to provide enterprises with better performance, cost efficiency, and operational agility in multicloud setups.
Why this matters: Expanding the Oracle-AWS multicloud partnership allows enterprises to leverage strengths of both clouds seamlessly, boosting flexibility and efficiency. Enhanced migration and management simplify complex environments, enabling improved performance and cost savings while supporting agile, scalable operations in increasingly hybrid cloud infrastructures.
DATABRICKS

TL;DR: Databricks reached a $5.4 billion revenue run rate by unifying data engineering, science, and analytics with its Lakehouse platform, accelerating AI-driven innovation and reshaping enterprise data ecosystems.
Databricks has reached a $5.4 billion revenue run rate, showcasing rapid growth in data intelligence.
The platform unifies data engineering, science, and analytics, accelerating innovation with AI-driven collaboration.
Databricks’ Lakehouse architecture combines data lakes and machine learning for scalable, efficient workflows.
Strategic partnerships and customer adoption position Databricks to reshape enterprise data and AI landscapes.
Why this matters: Databricks’ $5.4B run rate signals a major shift in enterprise data strategy toward unified, AI-powered platforms. Its Lakehouse architecture streamlines data and machine learning workflows, driving innovation and competitive advantage. Strong partnerships amplify its influence, potentially redefining data intelligence and AI integration industry-wide.
DATABASE PERFORMANCE

TL;DR: Snowpark enables autonomous agents in Snowflake for automating data workflows. Best practices emphasize modular design, clear behaviors, state management, error handling, and performance optimization for scalable, maintainable applications.
Agentic programming with Snowpark enables autonomous software agents to automate complex data workflows on Snowflake’s platform.
Best practices include modular code design, clear agent behavior definitions, effective state management, and robust error handling.
Optimizing performance involves leveraging lazy evaluation, caching, and balancing agent autonomy with control to avoid runaway processes.
These practices enhance automation scalability, improve decision speed, reduce manual work, and support maintainable, testable data applications.
Why this matters: Adopting agentic programming with Snowpark empowers organizations to automate and scale complex data workflows efficiently. Following best practices ensures robust, maintainable, and performant autonomous agents, accelerating decision-making while reducing risks and manual effort, paving the way for advanced cloud-native data applications and long-term success on Snowflake.

EVERYTHING ELSE IN CLOUD DATABASES
How Distributed Databases Ensure Data Replication
Databricks unveils Document Intelligence & Lakehouse
Top Airtable Alternatives for Full Control
BigQuery Graph powers scalable graph analytics on GCP
Matei Zaharia Wins 2025 ACM Computing Prize
ClickHouse integrates with Google BigLake for analytics
Amazon's Modular AI Data Centers Launch by 2026
Google Cloud boosts PostgreSQL with machine learning
Redpanda Connect syncs Salesforce with Oracle, DynamoDB
Data Pipeline Observability Market Soars in Growth
Cloudera Boosts Hybrid Data with Scale & Stability
Boost Big Data with Snowflake Iceberg Tables
Deploy PlanetScale Postgres Easily with Cloudflare Workers
Build fast DuckDB Python pipelines with SQL & Parquet
SageMaker Studio Boosts Notebook Analytics Speed
Cisco Acquires Galileo to Boost AI Observability Tools
DEEP DIVE
A look at Databricks Genie Code and my hands on experience
I was immersed this week at work with Databricks Genie Code. I was a real world, Production level usage of it and I would love to share the details of it, but I have to be very careful of what I share in this public forum.
I must say though that it works incredibly well and if you use Databricks in your day to day work, give it a try.
Check out the following technical deep dive on Databricks Genie code:
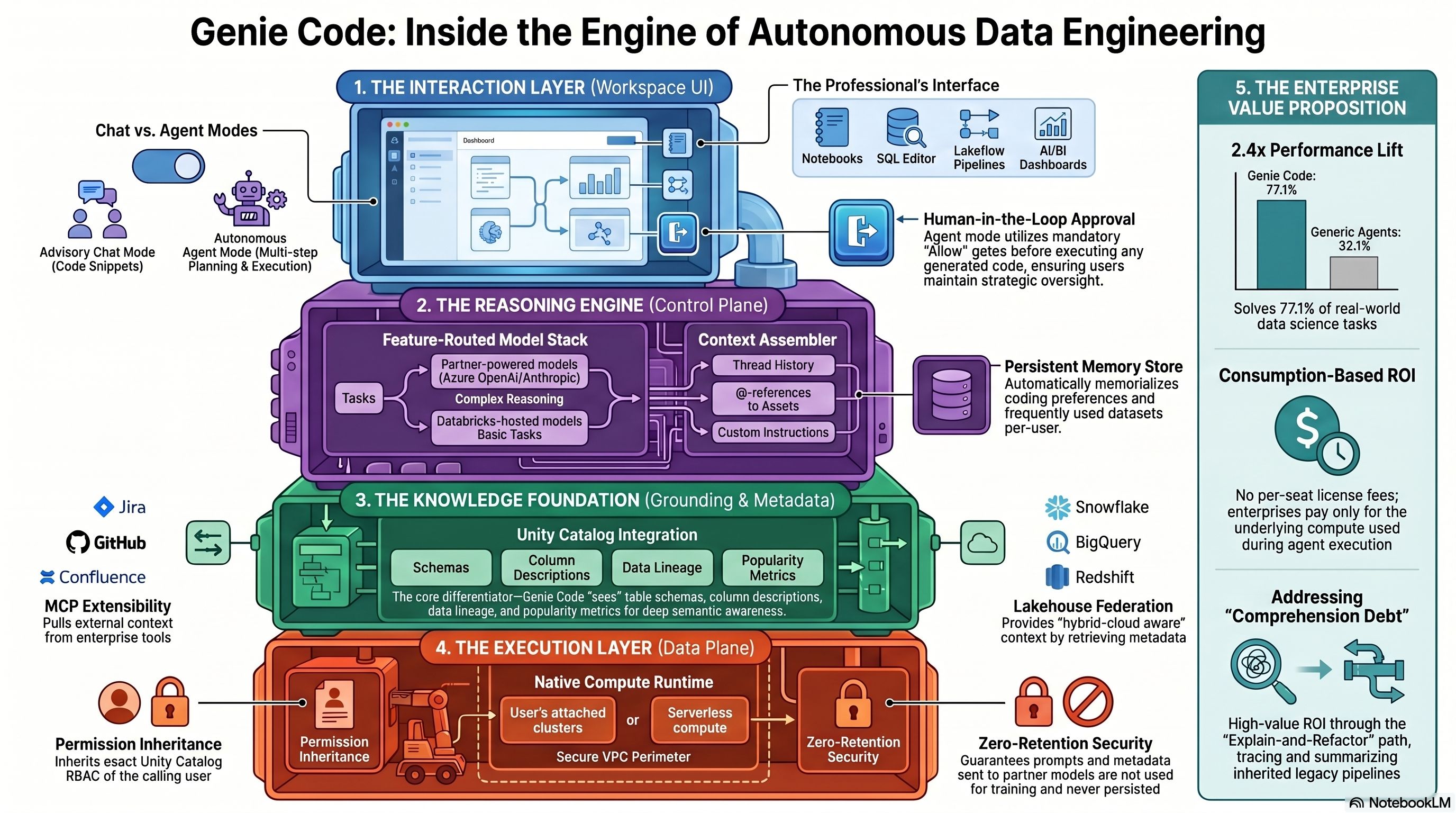
The first time Databricks shipped an AI coding helper, it was called the Databricks Assistant and it did roughly what every other in-IDE assistant did in 2024: autocomplete, explain-this-cell, fix-my-syntax. Useful, but unremarkable.
On March 11, 2026, Databricks retired that framing. What replaced it — Genie Code, now GA across AWS, Azure, and GCP — is not a coat of paint on the old Assistant. It is an autonomous agent that plans, asks clarifying questions, writes code across multiple files, runs it, reads the output, and iterates until the job is done or a human tells it to stop. In Databricks' own internal benchmark on real-world data-science tasks, Genie Code posted a 77.1% success rate against 32.1% for a leading general coding agent wired into Databricks' own MCP servers. Take the number with a pinch of salt — Databricks hasn't published the task set — but the direction of travel is clear.
This is Databricks planting a flag: data work is a different problem than software engineering, and it needs a different agent. Whether that thesis survives contact with regulated enterprises is the more interesting question.
What Genie Code actually is — and what it isn't
The Genie name now covers three distinct products, and confusing them is a recurring failure mode in customer conversations. Genie (sometimes "AI/BI Genie") is the conversational assistant that lets business users ask natural-language questions against a curated semantic layer and get SQL-backed answers. Genie spaces are the governed sandboxes — up to roughly 30 Unity Catalog tables per space — that give those conversations their context. Genie Code is the agent aimed at the people who build the pipelines, models, and dashboards that feed the other two.
Genie Code lives inside the workspace surfaces a data practitioner already works in: notebooks (Python, SQL, R, Scala), the SQL Editor, the Lakeflow Pipelines Editor, AI/BI Dashboards, MLflow 3.0 experiments, Catalog Explorer's sample-data view, and the generic file editor. It runs in two modes. Chat mode is the descendant of the old Assistant — Q&A, slash commands, autocomplete, explain-this-error. Agent mode is the new capability, and the only reason anyone cares about this launch.
The agent loop
Agent mode follows a pattern anyone who has watched Claude Code or Cursor's agent features will recognize: plan → clarify → execute → observe → iterate. What makes it interesting is how the surfaces specialize.
Ask Agent mode in a notebook to "forecast Q4 revenue by region," and it will go hunting through Unity Catalog for the relevant tables, propose a plan, ask you which revenue definition to use, show you the code it intends to run, wait for approval, run it, read the output distribution, and loop back if something looks off. Point it at the Lakeflow Pipelines Editor and the same agent adopts a data-engineering persona — it will refactor across multiple SQL and Python files, diff the changes for your review, run the pipeline, triage errors, and keep going until the DAG is green. Drop it into MLflow and it inspects traces, clusters failure patterns, and recommends scorers to add to your evaluation harness — though it's read-only here; it won't modify your experiments.
Two constraints worth flagging early. The first is the approval gate: before any action that writes, executes, or mutates state, Genie Code pauses and asks you to pick Allow, Allow in this thread, Always allow, or Decline. This is a real friction point for people who want fire-and-forget autonomy, but it is also the main reason regulated shops will be willing to touch it. The second is the stay-on-tab requirement: the agent loop halts if you navigate away in your browser. If you want your agent to churn for twenty minutes while you do something else, today it won't. Background agents for routine pipeline maintenance are on the roadmap — "schema mismatch auto-fix" ships as a background agent in an upcoming release — but the general case still requires you to keep the tab open.
What's under the hood
Genie Code does not run on a single model. It's a routed system. When Partner-powered AI features are enabled at the account and workspace level, Agent-mode traffic goes to partner endpoints — Azure OpenAI or Anthropic Sonnet-class models — hosted inside Databricks' own security perimeter with zero-retention terms and no training on customer data. When Partner-powered AI is off, the system falls back to Databricks-hosted open or OpenAI-OSS models, and Agent mode is largely unavailable. This toggle is the single most consequential decision a Databricks admin makes about Genie Code. Turn it off and you have a better autocomplete; turn it on and you have the agent Databricks is selling.
Three things make the agent more than the sum of its model calls.
Unity Catalog grounding is the headline differentiator. Every prompt is assembled in the control plane against a context bundle that includes UC table and column metadata, descriptions, primary/foreign keys where they exist, lineage, usage telemetry, favorite tables, and sample rows. This is the mechanism by which "analyze sales performance" gets turned into a specific join across specific tables with the aggregation your team actually uses. It is also why every Databricks customer, analyst, and community practitioner — most notably SunnyData in their two-weeks-later review — converges on the same warning: Genie Code's quality is entirely bounded by your Unity Catalog metadata hygiene. Point it at an undocumented data swamp and it will generate plausible, confident, wrong SQL at scale.
Skills are Databricks' answer to the customization problem. A skill is a SKILL.md file with YAML frontmatter and Markdown instructions, optionally bundled with scripts and reference files. Workspace skills live at Workspace/.assistant/skills/ and are admin-managed; user skills live in the user's home and are private. Skills get auto-loaded in Agent mode when relevant and can be invoked explicitly via @skill-name. This is where an organization encodes its PII masking rules, its approved CDC patterns, its revenue-definition canon. Databricks' Field Engineering team publishes an open-source ai-dev-kit of curated pipeline, Jobs, and dashboard skills. Expect the skill library to become a meaningful governance artifact — a versioned, Git-managed codification of "how we do data work here."
MCP — Model Context Protocol — is how Genie Code reaches outside the lakehouse. Databricks exposes three classes of servers: managed endpoints for UC functions, Vector Search indexes, and Genie spaces (authenticated on-behalf-of-user and governed by UC permissions); external managed OAuth connectors for GitHub, Google Drive, SharePoint, and Glean; and custom MCP servers that teams can host on Databricks Apps for proprietary tools. There's a hard ceiling: 20 tools across all MCP servers, total. Combined with the ~30-table limit on Genie spaces, this forces deliberate scoping. A team that naively wires in GitHub + Jira + Confluence + Drive + three UC schemas will blow the budget before lunch. Pre-unification into metric views and narrow skill folders is not optional for complex domains.
On top of all this sits persistent memory. Genie Code writes to ~/.assistant_instructions.md (user scope) and Workspace/.assistant_workspace_instructions.md (workspace scope, wins over user). These are Markdown files you can inspect. The agent updates them based on past interactions — preferred libraries, frequently-used tables, session patterns — and reads them on every response except Quick Fix and autocomplete. This is the surface where the Quotient AI acquisition (announced the same day as Genie Code) will matter most: Quotient's engineers led quality for GitHub Copilot, and their continuous-evaluation stack is designed to turn production traces into reward signals that fine-tune agent behavior over time.
The 77.1% number
Databricks' benchmark claim needs a closer read than most people have given it. The framing is: on "real-world data science and analytics tasks collected from internal users," Genie Code solved 77.1% versus 32.1% for a leading coding agent equipped with the same Databricks MCP servers. That's a 2.4x delta, which is large enough to matter if true, and Databricks has not published the task list, sample size, scoring rubric, or statistical significance.
Two things are probably true simultaneously. First, on tasks where the bottleneck is data context — which table, which join, which business definition — a UC-grounded agent with persistent memory and organizational skills should smoke a general coding agent. That's not a hard claim to believe; it's the whole pitch. Second, on tasks where the bottleneck is pure code synthesis, there's no obvious reason Genie Code would beat a frontier model in Cursor or Claude Code. Treat the number as directional internal data, not as a settled benchmark.
Competitive posture
Every hyperscaler and data platform shipped a version of this in the last eighteen months, and none of them look quite like Genie Code.
Snowflake Cortex Agents orchestrate Cortex Analyst (structured) and Cortex Search (unstructured) with a planning-and-reflection loop governed by standard Snowflake RBAC. It's the closest architectural analog. Microsoft Fabric fields Copilot per workload and Data Agents that enforce Fabric governance, with MCP now GA in Copilot Studio — a tight play inside the Microsoft estate. BigQuery Gemini offers SQL generation plus a Data Engineering Agent for pipeline creation. AWS takes the modular route with Bedrock AgentCore (runtime, memory, observability, identity as separate services) plus Amazon Q Developer in SageMaker Studio.
Genie Code's real differentiation isn't the agent loop — everyone has one now. It's three things: Unity Catalog as a first-class context substrate (nobody else has this depth of structured data grounding natively wired into the agent), no added license cost (you pay for the compute you consume, not for the agent itself — which is genuinely disruptive versus per-seat plays), and the unified workspace story — notebooks, pipelines, dashboards, and observability in one thread that travels with you across surfaces.
What will stop you
The limitations are not hypothetical and deserve to be on the first slide of any adoption conversation.
Non-determinism. Same prompt, different thread order, different code. Databricks recommends Trusted Assets, validated query patterns, and enforced methodology via Skills as mitigations. For SOX-critical financial reporting, none of these is a deterministic-output guarantee, and no "frozen plan" mode has been announced. If you generate your 10-K numbers, this is not the tool that generates them.
Geo gating. Genie Code is a Designated Service under Databricks Geos. Some workspaces must disable the "Enforce data processing within workspace Geography for AI features" toggle for cross-Geo processing — a live concern for EU, APAC, and Canadian regulated customers. FedRAMP High/Moderate, IRAP, and CCCS Protected B support remains partial; pay-per-token GenAI endpoints are the usual sticking point. Map this against your actual deployment before you commit.
Metadata dependency. Already said, worth saying again: performance is a function of UC quality. A hardening program (descriptions, PK/FK constraints, lineage, certified Trusted Assets) is a prerequisite, not a nice-to-have.
Cost opacity. Agent mode is iterative by design — it runs code, reads output, runs more code. Community analysis has clocked compute-intensive Agent tasks at roughly $3/hour in serverless DBUs. Multiply by an engineering team times dev/test/prod environments and budgets drift faster than per-seat licensing would have.
Memory governance. There is no documented API to inspect, export, or purge memory as of April 2026. For offboarding, GDPR right-to-erasure, and general least-privilege hygiene, this is a gap.
MCP prompt injection. Untrusted tool outputs from external MCP servers can carry adversarial instructions. Databricks' managed OAuth and UC permission model limits blast radius, but specific injection mitigations are not detailed. Treat external MCP like any untrusted input surface.
Who should lean in, who should wait
The clean framing: if Databricks is your primary data platform, your UC metadata is in reasonable shape, your compliance posture tolerates human-in-the-loop AI, and your teams have backlog on pipelines and dashboards — lean in. Genie Code is the highest-ROI agentic layer you can deploy today inside a Lakehouse, and the pricing is effectively "free with compute." Pilot in one workspace with curated workspace instructions and a small set of certified skills; the unit-of-risk is low.
If you're metadata-immature but have early-adopter culture, evaluate. Use the pilot to force the metadata-hardening work you needed to do anyway. The agent is a forcing function for governance hygiene, which is a feature, not a bug.
If your workspace sits in an unsupported Geo, your compliance profile blocks Partner-powered AI, or Databricks is a minority estate — actively defer. Deploying an autonomous agent into a chaotic data environment automates the generation of technical debt. Fix the foundation first.
The real bet
Genie Code's interesting claim is not that it writes better SQL than Cursor. It's that the unit of work in data engineering has shifted. It used to be "a cell, a query, a function." Databricks is betting it's now "a pipeline, a dashboard, an observability fix" — multi-asset, multi-surface, governed, iterated with a human checkpoint. If that framing holds, the data platforms that own the governance substrate (Unity Catalog, in this case) will own the agent layer on top of it, because nobody else can ground the agent the way they can.
The counter-bet — that general frontier coding agents plus well-designed MCP servers will eventually close the gap — is not crazy. MCP is a standard; the lakehouse isn't magic. Eighteen months from now, the 77.1% number will look either prescient or quaint.
For now, if you're on Databricks and your metadata is clean enough to trust, Genie Code is the most interesting thing to happen to your platform in a while. If your metadata isn't clean enough to trust, it's the most expensive way to discover that.
Gladstone Benjamin
🚀 Work With Cloud Database Insider
Looking to reach enterprise data engineers and architects?
Limited sponsorship slots available each month.