- Cloud Database Insider
- Posts
- Databases Evolve: From RDBMS to AI & Quantum Ready🚀
Databases Evolve: From RDBMS to AI & Quantum Ready🚀
Also, Convex is the anti-SQL database-The reactive database
Gladstone Benjamin
January 19, 2026
In partnership with
What’s in today’s newsletter:
Databases evolve with AI and quantum readiness 🚀
DOD adopts data mesh for Zero Trust 2027 🤖
Supabase launches Vector Buckets for AI search ➡️
SQL Server Standard 2025 boosts data management!🔄
Also, check out the weekly Deep Dive - The firestorm called Convex
The Future of Tech. One Daily News Briefing.

AI is moving faster than any other technology cycle in history. New models. New tools. New claims. New noise.
Most people feel like they’re behind. But the people that don’t, aren’t smarter. They’re just better informed.
Forward Future is a daily news briefing for people who want clarity, not hype. In one concise newsletter each day, you’ll get the most important AI and tech developments, learn why they matter, and what they signal about what’s coming next.
We cover real product launches, model updates, policy shifts, and industry moves shaping how AI actually gets built, adopted, and regulated. Written for operators, builders, leaders, and anyone who wants to sound sharp when AI comes up in the meeting.
It takes about five minutes to read, but the edge lasts all day.
DATA ARCHITECTURE

Source: hackernoon
TL;DR: Database technology is evolving from traditional RDBMS to AI-native and quantum-ready systems, leveraging machine learning for smarter operations and preparing for quantum computing, requiring updated skills and ongoing innovation.
Database technologies are evolving from traditional RDBMS to AI-native and quantum-ready systems for greater adaptability.
AI-native databases use machine learning for automated indexing, query optimization, and intelligent data retrieval.
Quantum-ready databases prepare for quantum computing by supporting quantum data structures and algorithms.
This evolution demands updated skills for professionals and continuous innovation to handle complex, large-scale data.
Why this matters: The shift to AI-native and quantum-ready databases transforms data management by enhancing efficiency, accuracy, and scalability. It prepares organizations for future computing paradigms, demanding new skills and continuous innovation to handle complex data, ultimately enabling faster, smarter decision-making and maintaining competitive advantage in a tech-driven world.

TL;DR: The DoD is adopting a decentralized data mesh approach to improve scalability, security, and data management, ensuring effective Zero Trust compliance and enhanced mission performance by the 2027 deadline.
The DoD is adopting a data mesh approach to support its 2027 Zero Trust Architecture implementation deadline.
Data mesh decentralizes data ownership, improving scalability, discoverability, and security across DoD systems.
This approach counteracts centralized data lakes’ bottlenecks and vulnerabilities in the DoD's complex environment.
Data mesh enables secure data management, timely analytics, and innovation, boosting DoD mission effectiveness.
Why this matters: The DoD’s shift to a data mesh model is critical for meeting stringent 2027 Zero Trust cybersecurity requirements, enabling secure, scalable, and agile data management. This decentralization enhances operational control, reduces vulnerabilities, and fosters innovation, thereby strengthening mission readiness against evolving cyber threats in complex defense environments.
VECTOR DATABASES

TL;DR: Supabase's Vector Buckets combine vector search and object storage, enabling real-time AI-driven similarity searches, simplifying infrastructure, and accelerating development of semantic search and recommendation applications.
Supabase launched Vector Buckets to integrate vector search and object storage for AI data management.
Vector Buckets enable real-time similarity searches by combining files with vector embeddings in one bucket.
The feature uses Hugging Face sentence transformer for efficient embedding creation and query processing.
This innovation reduces infrastructure complexity and boosts AI search functionality for developers and enterprises.
Why this matters: Supabase's Vector Buckets lower technical barriers by unifying vector search and storage, enabling faster development of AI-powered search features. This innovation advances accessible AI integration, pushing backend platforms toward seamless support for sophisticated AI applications, thereby accelerating innovation in personalized content and data-driven experiences.
RELATIONAL DATABASE
TL;DR: Microsoft SQL Server Standard 2025 offers scalable, secure, and cost-effective database solutions with enhanced AI analytics, high availability, and improved performance, ideal for mid-tier applications and growing businesses.
Microsoft SQL Server Standard 2025 supports up to 24 cores and 128 GB memory, ideal for mid-tier applications.
The release enhances performance, security, analytics, and reporting for AI and big data integration.
It includes high availability features like basic availability groups to ensure business continuity and minimize downtime.
The edition offers cost-effective, enterprise-grade database tools tailored for small to medium-sized enterprises.
Why this matters: Microsoft SQL Server Standard 2025 offers mid-sized businesses affordable, scalable, and secure database solutions with enhanced AI and big data analytics. By balancing enterprise-level features and cost, it empowers organizations to improve decision-making, ensure business continuity, and maintain compliance, strengthening Microsoft's competitive edge in the database market.

EVERYTHING ELSE IN CLOUD DATABASES
OpenSourceDB & Ahana boost PostgreSQL in banking
Weaviate Tops 2025 Vector DBs with AI Power
MySQL lag issue after capacity expansion resolved quickly
Top 10 MongoDB ETL Tools to Try in 2026
Percona debuts fixed-scope packages for open DBs
Alibaba vs Microsoft: AI cloud stock battle heats up
Boost PySpark Speed with Apache Arrow Integration
Databricks launches Instructed Retriever to boost AI accuracy
Algolia, Microsoft join to boost real-time shopping data
Build durable AI agents with LangGraph and DynamoDB
DEEP DIVE
Convex, the anti-SQL database
Convex is a little concerning to me to say the least. Never has such a data paradigm confounded, confused, and intrigued me all at the same.
Imagine manipulating data by making Typescript/Javascript function calls and not using anything of the likes of dataframes or stored procedures. I mean NO SQL to deal with from the developer perspective.
Here is a video that explains the previous sentence.
This is what Convex is.
I “discovered” Convex earlier this week when listening/watching a video by Theo - t3․gg.
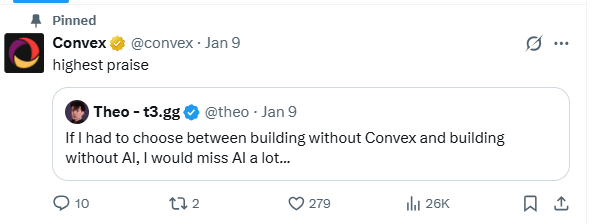
He was lamenting in his normal, subdued, non-profane style about the fall of Firebase and Supabase, and the whole world of developers migrating to Convex.
Even some other folks believe it is the utter end of all other types of the 1500 databases I keep track of:

This guy has obviously never worked in a Financial institutions technology department.
All I am going to say in this forum is always keep an open mind. At the same time, never dismiss anything outright.
All that I am going to do is my requisite research, and make up my own mind.
That is the key here with Convex.
One point to note is that I am still having an internal debate about even writing a section here about Convex which is a backend-as-a-service, but if they have sections on their website about Convex vs. Firebase, or Convex vs. Supabase, or Convex vs. SQL, they have already put themselves in the realm of cloud databases.
But before I go, here is a little primer about Convex:
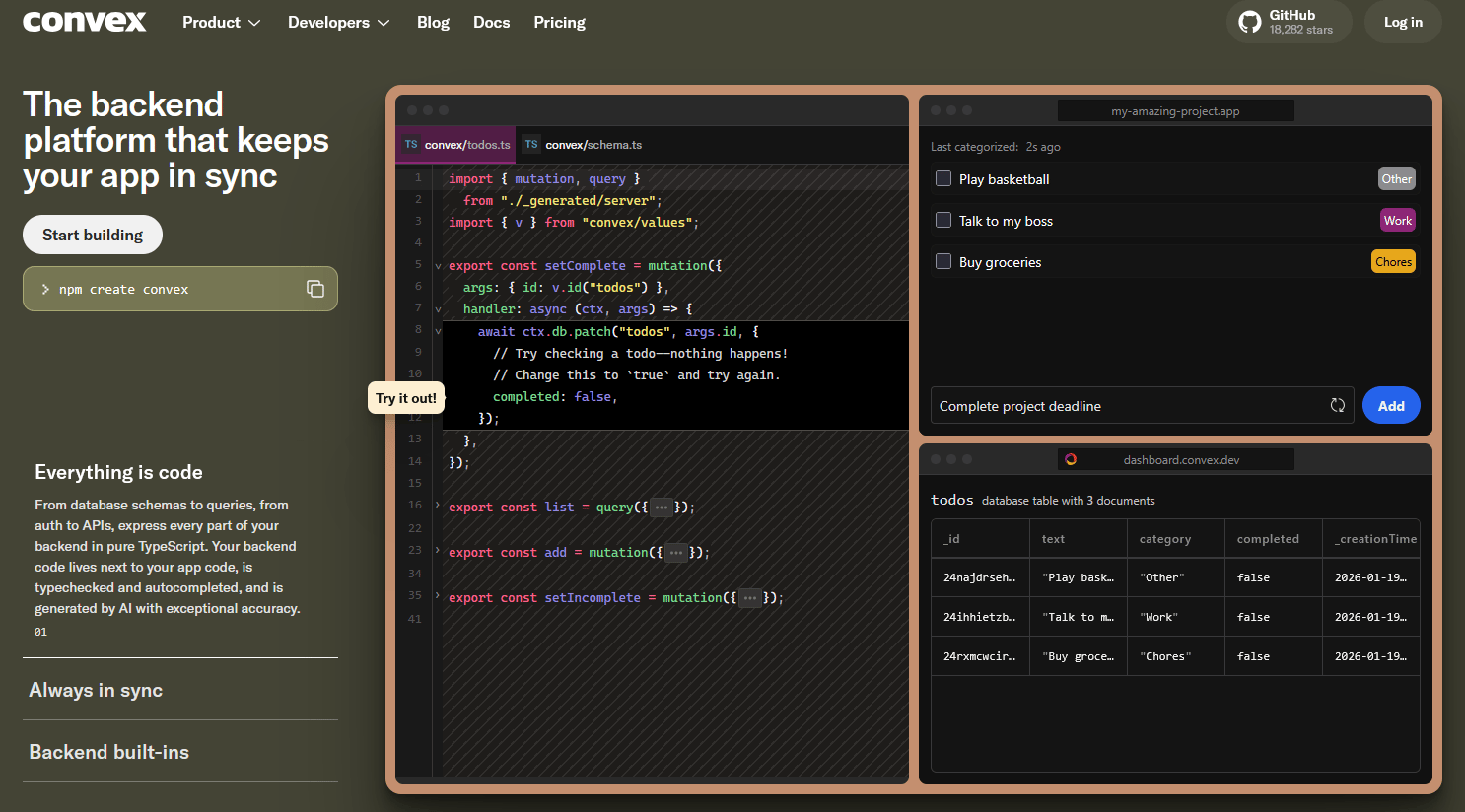
Convex isn't just a database; it’s a reactive backend-as-a-service that attempts to delete the "glue code" layer of modern web dev. It replaces the traditional stack of Database + API Server + ORM + Caching Layer + WebSocket Server with a single, deterministic runtime.
1. The Core Innovation: Deterministic Reactivity
The "magic" of Convex isn't that it's real-time (Firebase did that years ago); it's how it achieves reactivity.
How it works: You write backend functions in TypeScript (Queries). These functions run in a deterministic, isolated environment.
Dependency Tracking: Because execution is deterministic, Convex knows exactly which database documents a query accessed. It builds a precise dependency graph.
Automatic Invalidation: When a mutation changes a document, Convex instantly knows which queries depended on that specific document and re-runs only those queries, pushing the new result to the client via WebSocket.
The Benefit: You never write subscription logic,
useEffectfor data fetching, or cache invalidation code. The "API" effectively behaves like a live variable in your frontend component.
2. Features
"Everything is Code" (ACID & Transactions):
Unlike Firestore's limited transaction capabilities, Convex mutations are full ACID transactions. If a function fails, the entire operation rolls back.
It uses Serializable Isolation, the highest level of isolation, meaning you don't have to worry about race conditions or "read anomalies" common in other distributed databases.
Convex Components (New Architecture):
Think of these as "npm packages for backends." Instead of just importing a library, you import a fully functional backend slice (e.g., a Sharded Counter, a Stripe sync engine, or Auth).
Sandboxing: These components run in their own isolated namespace with their own tables and schema, so they can't accidentally break your main app's data integrity.
Convex Chef (The AI Angle):
Because Convex uses TypeScript functions rather than SQL queries + messy infra config, it is arguably the most "LLM-native" backend.
"Chef" is their AI agent that can build full-stack apps because it only has to generate TypeScript logic, not complex Terraform or SQL migration scripts.
3. The Caveats & Trade-offs
For a balanced deep dive, you must mention these:
Vendor Lock-In: This is the biggest friction point. You are not just using a Postgres DB you can host elsewhere; you are writing code against their proprietary runtime. While they open-sourced the backend (written in Rust), self-hosting it for production is non-trivial compared to spinning up a Dockerized Postgres container.
The "Joins" Debate: Convex is a document store (NoSQL). You don't write SQL
JOINs. Instead, you write TypeScript that fetches data (effectively "application-level joins").Pro: Easier to reason about and type-safe.
Con: Can be less performant for complex analytical queries (OLAP) compared to a raw SQL engine, though Convex handles typical OLTP (app traffic) loads extremely well due to caching.
Pricing Model: You pay for function execution and database storage/bandwidth. Inefficient code (e.g., a query that scans the whole table) directly costs you money, whereas in a fixed-cost VPS/RDS setup, it just spikes your CPU.
4. Competitive Positioning
vs. Supabase: Supabase is "Just Postgres" with tools around it. If you love SQL and want total portability, Supabase wins. If you want to write zero backend infrastructure code and want "React-like" state synchronization, Convex wins.
vs. Firebase: Convex is effectively "Firebase 2.0" for the TypeScript era. It solves Firebase's biggest headaches: lack of type safety, poor transaction support, and the difficulty of complex queries (relational data).
Summary
"Convex is betting that the future of backends isn't a better database, but a better runtime. By forcing all interaction through deterministic TypeScript functions, they've automated the hardest problem in UI development: cache invalidation and state synchronization. It’s an opinionated, 'high-lock-in, high-velocity' tool that feels like magic for product engineers."
Gladstone Benjamin