- Cloud Database Insider
- Posts
- 87K MongoDB Servers Exposed by MongoBleed Flaw⚠️
87K MongoDB Servers Exposed by MongoBleed Flaw⚠️
Also, a real world discussion about modern Data Architecture (nothing textbook here)
Gladstone Benjamin
January 05, 2026
In partnership with
What’s in today’s newsletter:
Mongobleed flaw exposes 87K MongoDB instances globally⚠️
Snowflake Eyes $1B Acquisition of Observe❄️💰
Vector databases revolutionize content design and discovery 🚀
Apache Gravitino 1.10 Boosts AI Lakehouse Metadata🏞️🏠
Also, check out the weekly Deep Dive - Modern Data Architecture
The Future of AI in Marketing. Your Shortcut to Smarter, Faster Marketing.

Unlock a focused set of AI strategies built to streamline your work and maximize impact. This guide delivers the practical tactics and tools marketers need to start seeing results right away:
7 high-impact AI strategies to accelerate your marketing performance
Practical use cases for content creation, lead gen, and personalization
Expert insights into how top marketers are using AI today
A framework to evaluate and implement AI tools efficiently
Stay ahead of the curve with these top strategies AI helped develop for marketers, built for real-world results.
NOSQL

TL;DR: The Mongobleed vulnerability exposes 87,000 MongoDB instances by bypassing authentication and leaking credentials, highlighting risks in default or misconfigured setups and prompting urgent security audits and patches.
The Mongobleed vulnerability exposes around 87,000 MongoDB instances to unauthorized root access and data breaches.
It exploits security flaws in MongoDB’s command handling, especially in default or misconfigured access controls.
Researchers showed how easily attackers can leak credentials and sensitive data by abusing this weakness.
Urgent action is needed for audits, patching, and stronger security practices to protect affected MongoDB deployments.
Why this matters: With 87,000 MongoDB instances vulnerable, widespread data theft and ransomware risks escalate, threatening critical business operations. Mongobleed exposes fundamental security oversights in default configurations, pressuring organizations to urgently strengthen database defenses and rethink cloud security strategies to prevent catastrophic breaches.
SNOWFLAKE
TL;DR: Snowflake plans to acquire Observe for $1 billion, expanding beyond data warehousing into real-time data observability, enhancing reliability, monitoring, and aligning with trends toward comprehensive cloud data ecosystems.
Snowflake is in advanced talks to acquire data observability startup Observe for around $1 billion.
Observe provides real-time insights into data flows and detects discrepancies in cloud environments.
The acquisition would expand Snowflake’s capabilities beyond warehousing into data reliability and monitoring.
Integrating Observe reflects industry trends to create holistic data ecosystems with enhanced governance.
Why this matters: Snowflake’s potential $1 billion acquisition of Observe signals a strategic shift towards comprehensive data lifecycle management, emphasizing data reliability and real-time monitoring. This enhances Snowflake’s competitive edge, meets growing enterprise demands, and highlights the rising importance of observability in maintaining data quality within complex cloud ecosystems.
VECTOR DATABASE
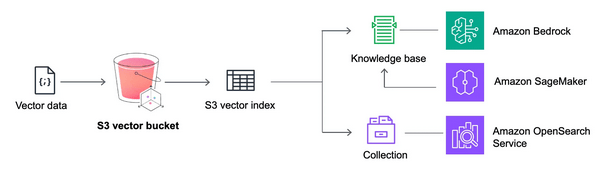
TL;DR: Vector databases revolutionize content design by enabling semantic, context-aware searches of unstructured data, enhancing creative discovery, personalization, and scalability for faster innovation and efficient content strategies.
Vector databases transform content design by managing complex data with context-aware, semantic search capabilities.
They convert unstructured data into vectors, enabling precise similarity searches beyond traditional keyword matching.
Integration with creative platforms enhances discovery and personalization, accelerating innovation for designers and marketers.
Vector databases improve scalability, reduce information overload, and enable more effective content strategies across industries.
Why this matters: Vector databases revolutionize content discovery by enabling semantic, context-driven search beyond keywords, significantly enhancing creative workflows. This leads to faster innovation, personalized experiences, and better management of complex data, addressing scalability challenges and information overload in content-rich industries across the digital landscape.
DATA LAKEHOUSE

TL;DR: Apache Gravitino 1.1.0 improves unified metadata management across diverse data systems, enhancing AI-native lakehouse architectures with better integration, data governance, and support for AI and analytics workflows.
Apache Gravitino 1.1.0 enhances unified metadata management within AI-native lakehouse architectures.
It supports diverse data formats, integrates with catalogs, and boosts AI/ML metadata capabilities.
The release simplifies data discovery, lineage tracking, and governance across heterogeneous storage systems.
Gravitino 1.1.0 reduces operational complexity and improves data reliability for AI and analytics workflows.
Why this matters: Apache Gravitino 1.1.0 streamlines metadata management in AI-native lakehouses, crucial for handling diverse data landscapes. This unification enhances data governance, accelerates AI/ML workflows, and reduces complexity, empowering organizations to innovate faster and build more reliable, secure, and scalable AI-driven data infrastructures.

EVERYTHING ELSE IN CLOUD DATABASES
AWS Outage Hits Top Games on Christmas Day
GizmoSQL: Simplifying Complex SQL Queries Fast
Milvus Tops 40K GitHub Stars in Vector DB Race
Microsoft vs Amazon: Who Leads Cloud in 2026?
Datadog: Key AI & Cloud Era Monitoring Tool
Kioxia boosts Milvus DB with AI SAQ Tech
Pinecone Boosts Vector AI with Distributed DRN Support
Data Shifts Powering Enterprise AI Growth in 2026
SQLite Powers On-Device AI with SQL Vector Search
PgBadger v1.32 boosts PostgreSQL log analysis speed
Is Your Data, Not Security, the Real Issue?
Top 10 Open-Source NoSQL Databases for 2026
DEEP DIVE
Modern Data Architecture
I am pretty sure I earned my keep in last month in the real world, if you know what I mean. I always have to be purposefully vague when it comes to work I do, but for this instance I can share some salient details without contravening any non-disclosure details.
I think we can all benefit from this.
Let’s just say that I had to look at different modern data architectures such as Data Federation and Data Virtualization. I researched both and then came up with a practical recommendation, based on extenuating circumstances.
When conducting such an exercise, you have to weigh the costs of using the technology you already have in place versus sourcing additional 3rd party solutions.
There are several other considerations such as security, compute, table formats like Delta Lake and Apache Iceberg, and egress costs, data governance, potential procurement, and above everything else, satisfying the needs of the ultimate data consumers.
This is a lot more than getting a database into third normal form.
One also has to hone their architecture diagramming skills. I will admit that this is not my strongest suit, but I had to persevere through it.
It was a very challenging exercise nonetheless and it was indeed a learning experience.
To wrap everything up, here are some of the technologies I explored:
File Formats:
ORC: Optimized Row Columnar (ORC) is a self-describing, columnar storage format optimized for large-scale analytics on Hadoop ecosystems, offering advanced compression, predicate pushdown, and efficient reads for Hive/Presto queries.
AVRO: Avro is a compact, schema-based serialization format ideal for data exchange in streaming systems like Kafka, supporting schema evolution and efficient binary encoding for evolving datasets.
Parquet: Apache Parquet is a widely adopted columnar storage file format designed for efficient analytics, with strong compression, encoding, and support for nested data in big data ecosystems like Spark and Hive.
"Flat Files": Flat files refer to simple, unstructured text-based formats like CSV or TSV, easy to generate/read but inefficient for large-scale queries due to lack of compression and columnar optimization.
JSON: JSON (JavaScript Object Notation) is a lightweight, semi-structured text format for storing and exchanging hierarchical data, flexible for APIs but row-oriented and verbose for analytical workloads.
Lance: Lance is a modern columnar format optimized for multimodal AI/ML workloads, enabling fast random access, vector indexing, versioning, and efficient handling of images/embeddings directly in data lakes.
Nimble: Nimble is Meta's experimental columnar file format (Parquet successor), designed for wide schemas with thousands of columns, extensibility, and parallel/GPU-friendly processing in ML feature engineering.
Vortex: Vortex is an extensible, high-performance columnar file format (Linux Foundation project) focused on compressed Arrow arrays, offering superior scan speeds, random access, and custom encodings for advanced analytics.
Table Formats:
Apache Iceberg: Apache Iceberg is an open table format for huge analytic tables, providing schema evolution, partitioning, time travel, and reliable ACID transactions on data lakes without tying to a specific engine.
Delta Lake: Delta Lake is an open-source storage layer adding reliability to data lakes with ACID transactions, schema enforcement, time travel, and unified batch/streaming on formats like Parquet.
Hudi: Apache Hudi is a lakehouse table format enabling upsert/delete operations, incremental processing, and efficient change data capture for near-real-time analytics on streaming data.
OneLake: OneLake is Microsoft's unified data lake in Fabric, built on ADLS with shortcuts for multi-format access, enabling seamless analytics across Delta, Parquet, and other sources without duplication.
Other Platform (Fed/Virt.):
StarRocks: StarRocks is a high-performance OLAP database supporting real-time analytics, federated queries, and materialized views for unified batch/real-time processing.
GlareDB: GlareDB is an open-source SQL database for querying and joining distributed data across sources (e.g., Postgres, S3, Snowflake) via federation, without data movement.
AtScale: AtScale is a semantic layer platform providing virtual multidimensional cubes and federated queries for business intelligence, abstracting complexity from tools like Power BI or Tableau.
Architectural Considerations:
Data Virtualization - Caching: Data virtualization often incorporates caching mechanisms to store frequently accessed query results locally, reducing latency and source system load in federated environments.
Data Federation - Push down: Data federation relies on predicate/filter pushdown to delegate computations (e.g., filters, aggregations) to underlying sources, minimizing data transfer and improving performance.
Security Considerations: In modern architectures, security involves row/column-level access, encryption at rest/transit, unified governance (e.g., via catalogs), and integration with tools like Ranger or Lake Formation.
Platforms:
Snowflake: Snowflake is a cloud data platform separating compute from storage for elastic scaling, with features like virtual warehouses, external tables, and native support for semi-structured data.
Databricks: Databricks is a unified lakehouse platform built on Spark, offering collaborative notebooks, Delta Lake management, and AI/ML workflows on cloud storage.
Microsoft Fabric: Microsoft Fabric is an end-to-end analytics solution centered on OneLake, integrating data engineering, science, warehousing, and real-time intelligence in a SaaS model.
Virt + Fed. Services Platforms:
Trino: Trino (formerly PrestoSQL) is a distributed SQL query engine for federated analytics across diverse data sources, excelling at high-concurrency queries without storage.
Dremio: Dremio is a data lakehouse platform providing self-service analytics, query federation, and acceleration via reflections on sources like S3 or databases.
GCP BigQuery OMNI: BigQuery Omni is Google's multi-cloud extension of BigQuery, enabling federated queries on data in AWS S3 or Azure without movement, using Anthos-powered compute.
Presto DB: PrestoDB is the original distributed SQL engine (now part of Trino lineage) for fast, interactive queries across heterogeneous data sources in federation setups.
Denodo: Denodo is a data virtualization platform delivering real-time, unified views across sources with caching, security, and abstraction for enterprise integration.
Azure Synapse Serverless: Azure Synapse Serverless is an on-demand query service for federated analytics over data lakes/files in ADLS, without provisioning compute.
Starburst: Starburst is an enterprise distribution of Trino, offering enhanced federation, security, and management for querying distributed data lakes/sources.
Ahana Cloud: Ahana Cloud was a managed SaaS for Presto on AWS, simplifying deployment and federation for open data lakehouses (note: service has evolved/post-acquisition).
Snowflake External Tables: Snowflake External Tables allow querying data in cloud storage (e.g., S3) without ingestion, enabling lightweight federation with staged files.
Databricks SQL + Lakehouse Federation: Databricks Lakehouse Federation provides unified governance and querying across external catalogs/sources (e.g., Hive, Unity) from Delta Lakehouse.
Gladstone Benjamin